0 前言
基于 centos7.9 docker-ce-20.10.18 kubelet-1.22.3-0 kube-prometheus-0.10 prometheus-v2.32.1
1 告警规则
prometheus 支持两种类型的规则, 记录规则 recording rule 和告警规则 alerting rule
1.1 recording rule
记录规则: 允许预先计算经常需要或计算量大的表达式,并将其结果保存为一组新的时间序列。查询预先计算的结果通常比每次需要时都执行原始表达式要快得多。这对于每次刷新时都需要重复查询相同表达式的仪表板特别有用。
如下示例, 将统计 cpu 个数的表达式存为一个新的时间序列 instance:node_num_cpu:sum
groups:
- name: node-exporter.rules
rules:
- record: instance:node_num_cpu:sum
expr: |
count without (cpu, mode) (
node_cpu_seconds_total{job="node-exporter",mode="idle"}
)
原始表达式结果
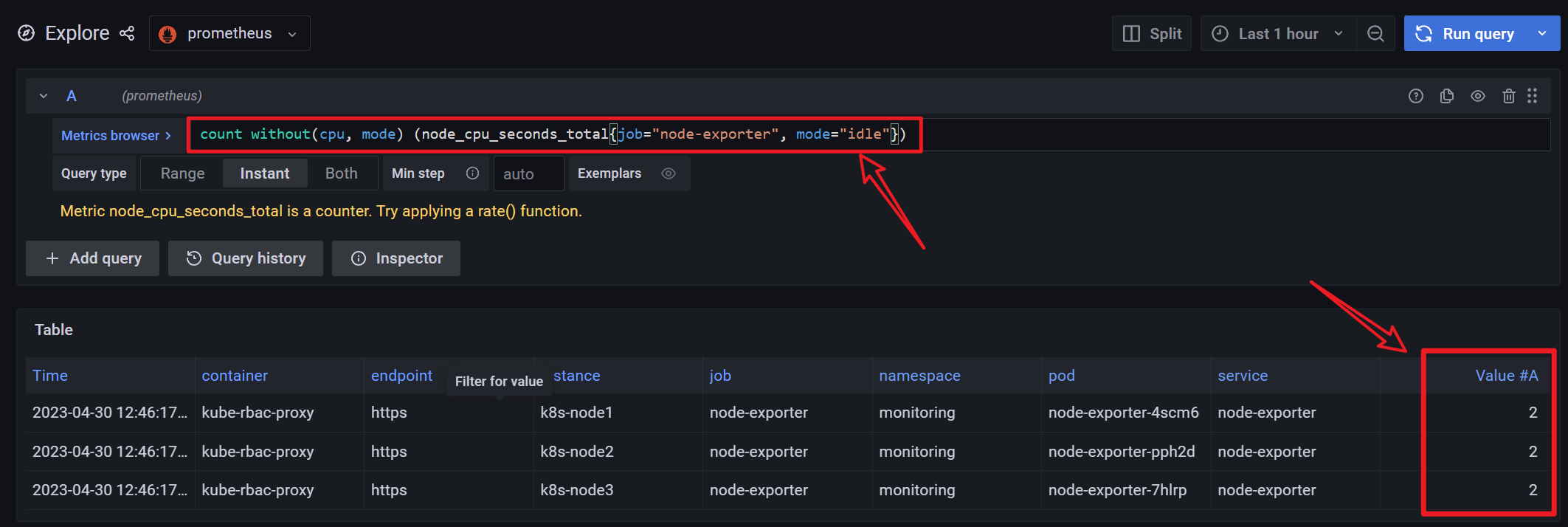
新表达式结果
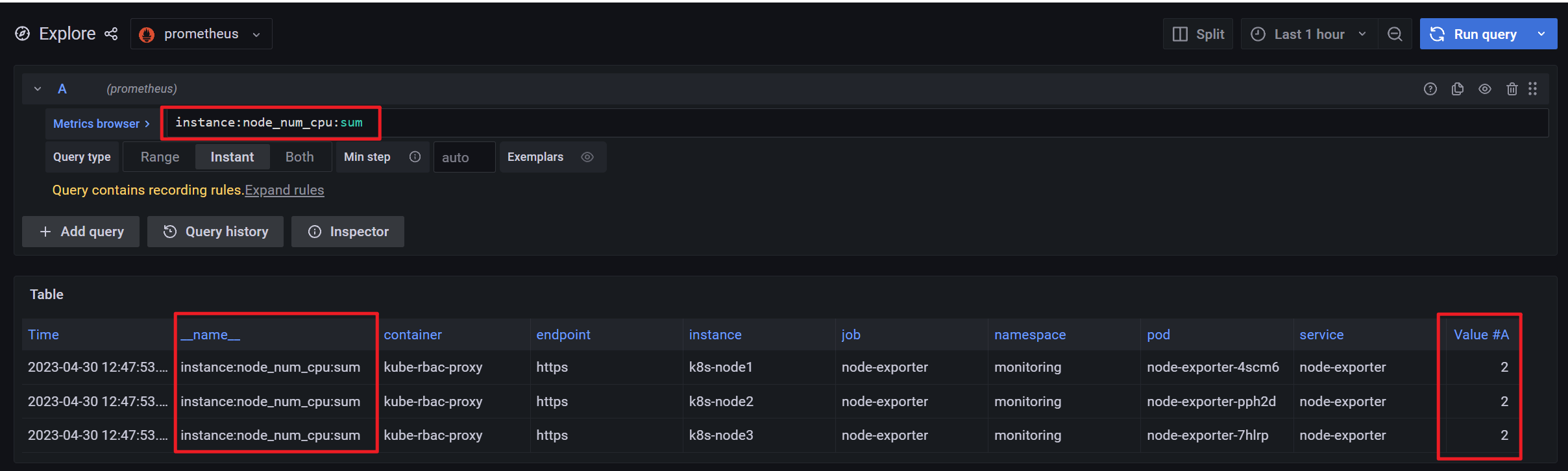
1.2 alerting rule
告警规则: 当满足指定的触发条件时发送告警
- alert: 告警规则的名称
- expr: 告警触发条件, 基于 PromQL 表达式, 如果表达式执行结果为
True则推送告警 - for: 等待评估时间, 可选参数. 表示当触发条件持续一定时间后才发送告警, 在等待期间告警的状态为
pending - labels: 自定义标签
- annotaions: 指定一组附加信息, 可以使用
$labels$externalLabels$value格式化信息.$labels储存报警实例的时序数据;$externalLabels储存 prometheus 中global.external_labels配置的标签;$value保存报警实例的评估值- description: 详细信息
- summary: 描述信息
如下示例, 当节点的某个文件系统剩余空间不足 10% 达到 30 分钟后将发送告警
groups:
- name: test
rules:
- alert: NodeFilesystemAlmostOutOfSpace
expr: node_filesystem_avail_bytes{job="node-exporter",fstype!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 10
for: 30m
labels:
severity: warning
annotations:
description: ' {{ $labels.instance }} 节点 {{ $labels.device }} 文件系统剩余空间: {{ printf "%.2f" $value }}% '
summary: '文件系统剩余空间不足 10%'
1.3 prometheusrule CRD
Prometheus Operator 抽象出来一个 prometheusrule CRD 资源, 通过管理这个 CRD 资源实现告警规则的统一管理
kube-prometheus 默认帮我们创建了一些告警规则
# kubectl get prometheusrule -A
NAMESPACE NAME AGE
monitoring alertmanager-main-rules 8d
monitoring kube-prometheus-rules 8d
monitoring kube-state-metrics-rules 8d
monitoring kubernetes-monitoring-rules 8d
monitoring node-exporter-rules 8d
monitoring prometheus-k8s-prometheus-rules 8d
monitoring prometheus-operator-rules 8d
prometheusrule 定义一系列报警规则
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
name: demo
namespace: monitoring
spec:
groups:
- name: group1
rules:
- alert: alert1
annotations:
description: alert-1
summary: alert-1
expr: up == 0
for: 15m
labels:
severity: critical
- alert: alert2
......
- name: group2
rules:
- alert: alert3
......
对于 prometheusrule 的更新操作 (create, delete, update) 都会被 watch 到, 然后更新到统一的一个 configmap 中, 然后 prometheus 自动重载配置
每个 prometheusrule 会作为 configmap prometheus-k8s-rulefiles-0 中的一个 data , data 的命名规则为 <namespace>-<rulename>-ruleuid
# kubectl get cm prometheus-k8s-rulefiles-0 -n monitoring
NAME DATA AGE
prometheus-k8s-rulefiles-0 7 41m
# prometheus 实例的挂载信息
# kubectl get pod prometheus-k8s-0 -n monitoring -o jsonpath='{.spec.volumes[?(@.name=="prometheus-k8s-rulefiles-0")]}' | python -m json.tool
{
"configMap": {
"defaultMode": 420,
"name": "prometheus-k8s-rulefiles-0"
},
"name": "prometheus-k8s-rulefiles-0"
}
# prometheus 中实际的存储路径
# kubectl exec -it prometheus-k8s-0 -n monitoring -- ls /etc/prometheus/rules/prometheus-k8s-rulefiles-0/
monitoring-alertmanager-main-rules-79a2aba8-1a50-4bbc-b201-e9c8ee43e6aa.yaml
monitoring-kube-prometheus-rules-9867eba7-cd4c-4677-b931-4268744ae5e7.yaml
monitoring-kube-state-metrics-rules-b787fea0-dba2-4d6d-9fd6-0b470ce45059.yaml
monitoring-kubernetes-monitoring-rules-b1939032-6a22-4ce1-b0ce-6482db094018.yaml
monitoring-node-exporter-rules-0140bdd4-b858-4672-85be-930eabdc95eb.yaml
monitoring-prometheus-k8s-prometheus-rules-87a80a69-f3be-4d3e-8a26-e1da2ade3a0a.yaml
monitoring-prometheus-operator-rules-8688aa7b-a157-4ddc-bd09-21781f8ac567.yaml
prometheus 的配置中定义了 rule_files 路径
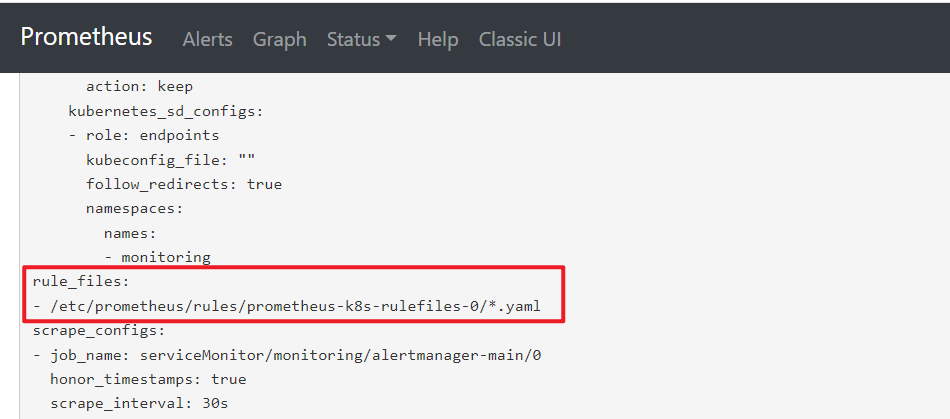
2 示例
2.1 磁盘使用率
当磁盘可用空间少于 50% 时触发告警
创建 prometheusrule
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: demo
namespace: monitoring
spec:
groups:
- name: demo
rules:
- alert: nodeDiskUsage
annotations:
description: |
节点 {{$labels.instance }}
挂载目录 {{ $labels.mountpoint }}
当前可用空间 {{ printf "%.2f" $value }}%
summary: |
挂载目录可用空间低于 50%
expr: |
node_filesystem_avail_bytes{fstype!="",job="node-exporter"} /
node_filesystem_size_bytes{fstype!="",job="node-exporter"} * 100 < 50
for: 1m
labels:
severity: warning
查看生成的告警规则, 当前状态是 inactive
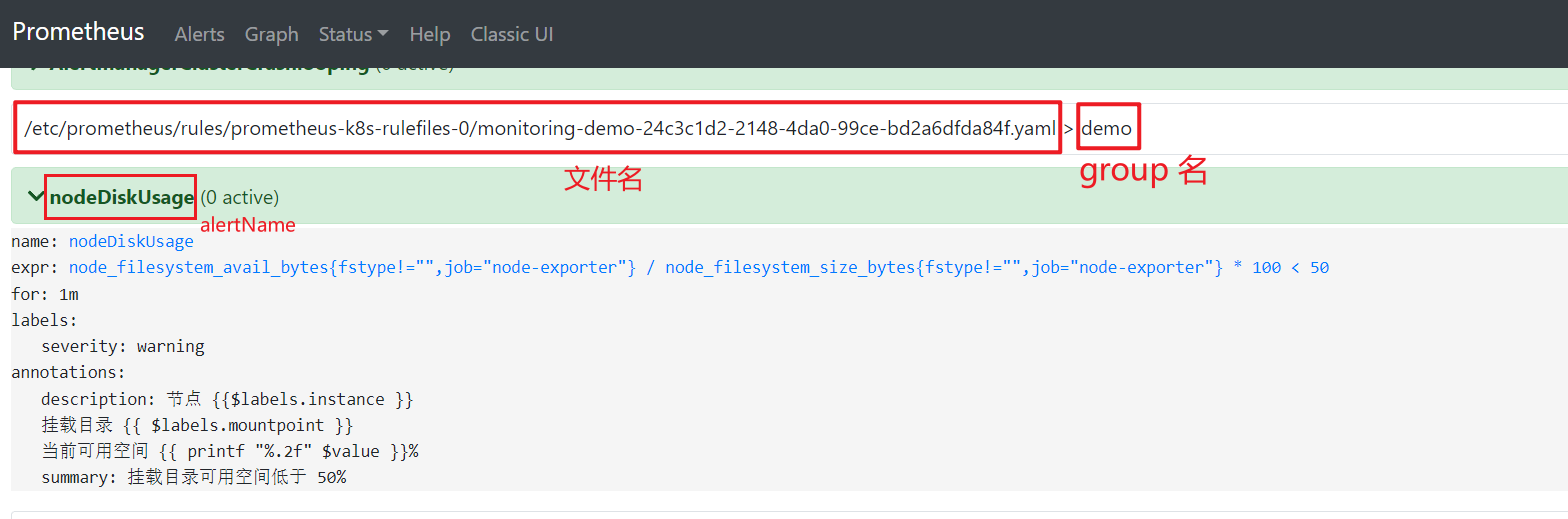
node1 当前状态, / 目录总容量 45G, 可用空间为 82%
[root@k8s-node1 manifests]# df -hT | head -1 && df -hT | grep -E "/$"
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/centos_one-root xfs 45G 7.8G 38G 18% /
接下来用 dd 手动创建一个 25G 的大文件, 此时剩余空间仅剩 27%
[root@k8s-node1 manifests]# dd if=/dev/zero of=/tmp/demo bs=1G count=25
[root@k8s-node1 manifests]# df -hT | head -1 && df -hT | grep -E "/$"
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/centos_one-root xfs 45G 33G 13G 73% /
此时告警规则已经进入 pending 状态了, 我们设置了 1m 的评估等待时间
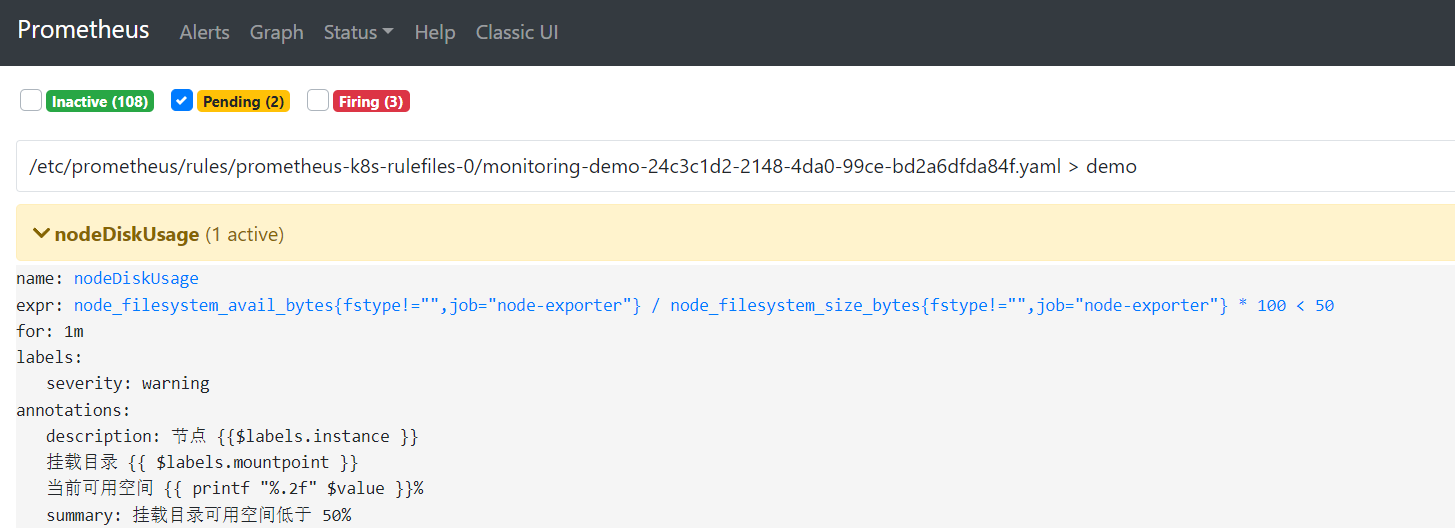
一分钟过后进入 firing 状态, 正式发出告警, 此时我们设置的 $label 还没有解析
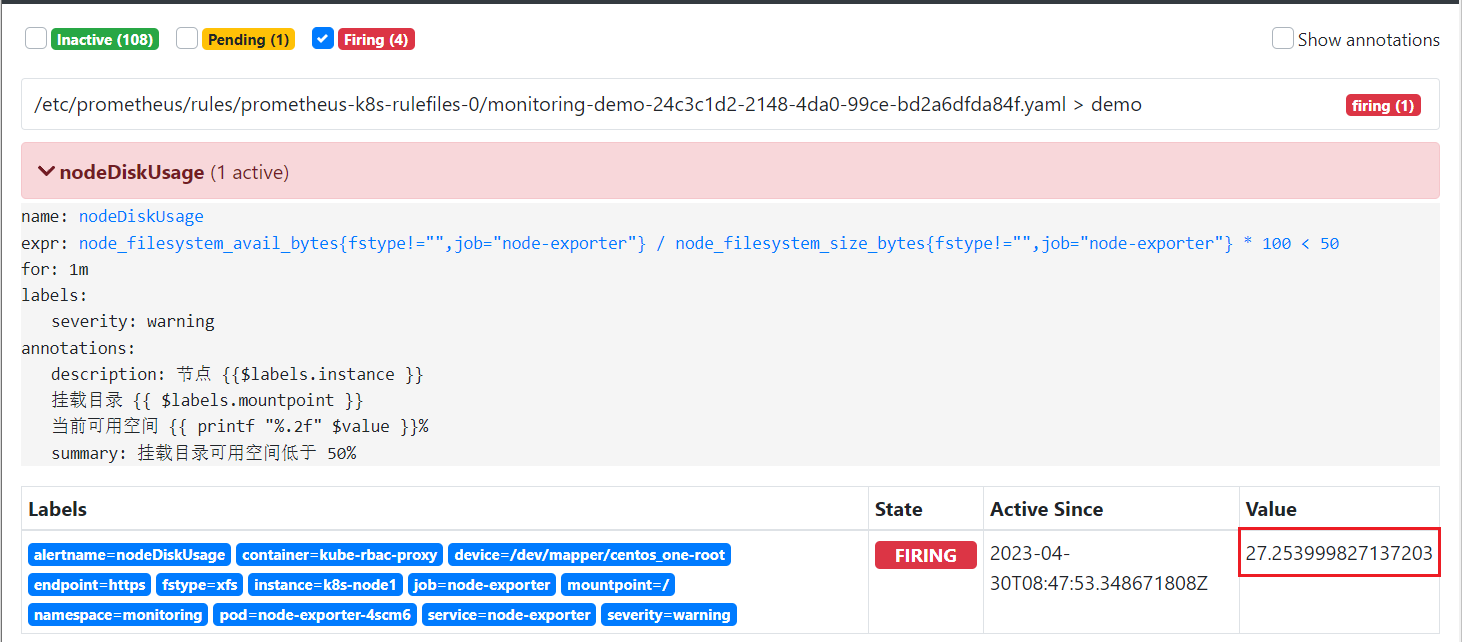
我们去 alertmanager 看一下, 成功收到了告警, 且 $labels 和 $value 也已经正常解析了
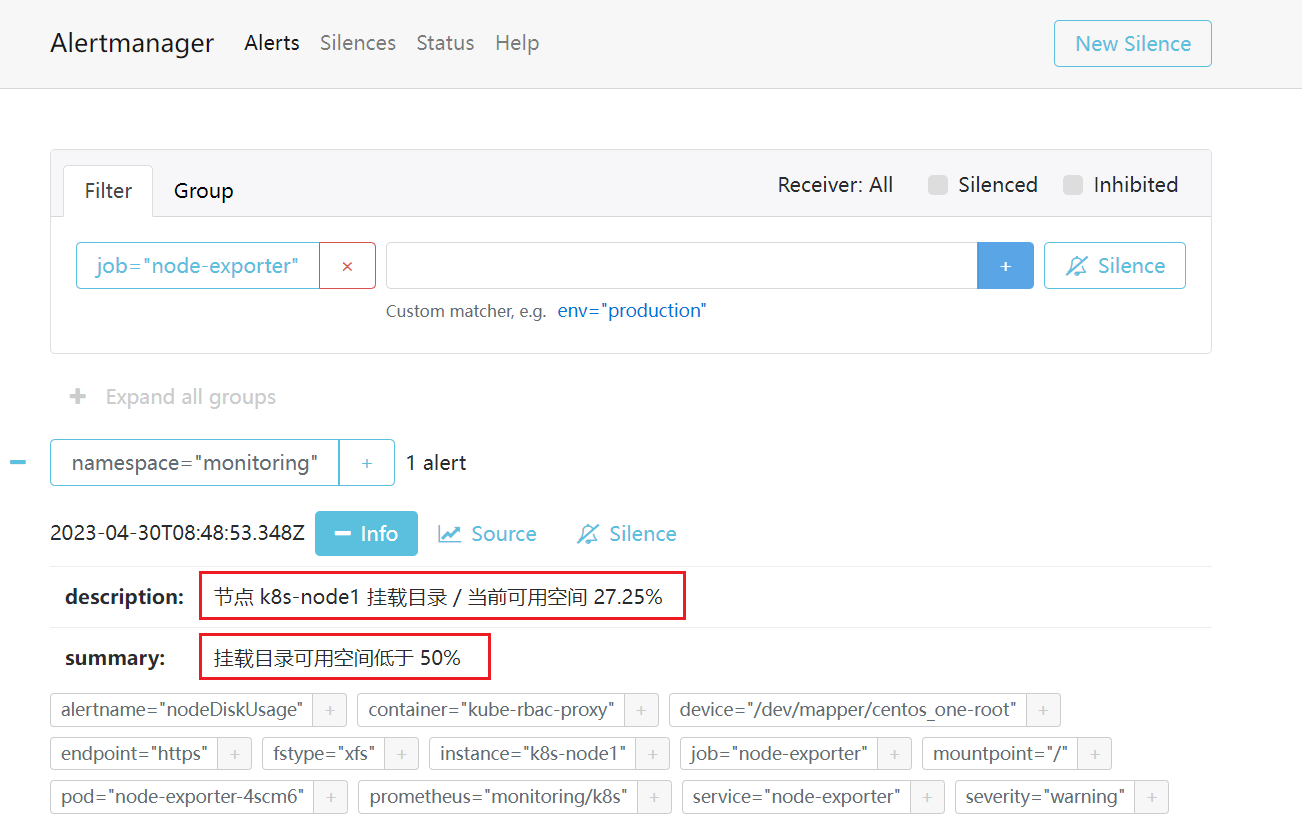
以上

